


〔視覺化〕字形檢索、動態歸類、筆畫解析、簡繁通查,全面學習中文。
中文是屬於〔形音分離〕的文字,僅使用同一種文字作為載體,而容納了多種不同發音的方言,在各方面都有別於西方〔口語化〕的文字。但現代的中文教育卻直接採用西方文字的教學方式,人們從小就習慣了個別而零碎的記憶詞句,當代字典也都只有提供詞句的單純解釋,而缺少〔字形解析、字形檢索〕等功能,如此很容易就會邊學邊忘,學得再久還是會感覺都是在死背詞句,中文的程度並沒有相對的提升。
其實中文是一種很典型的〔模組化〕文字,每個字詞的意義都是有理可循的。西方文字是以〔字母〕去拼出符合口語的〔字彙〕,因此〔文字〕與〔口語〕會互相牽制,難以保留造字的完整結構,且必須不斷的創造〔新單字〕以應付各種〔新名詞〕。而中文完全是以〔字形〕作為組字的元素,不受口語的牽制,古人先以〔偏旁造字〕充分保留了文字結構,而後人再以〔單字造詞〕產生出各種的〔新詞彙〕,不論是〔造字〕或〔造詞〕都具有明顯的〔模組化〕特性。
既然中文的每個〔字形圖象〕都具有超越〔口語〕的深遠意境,蘊涵了許多聯想的元素,那麼只要先瞭解了每個文字的組成結構,就必定能提升中文的學習效率。但問題是中文的單字數量很多,基本的入門就已經很有困難,然而中文的難學之處,並不在於字數繁多、艱澀難懂,而是在於檢索不易,無法觸類旁通,這是因為中文是屬於〔模組化〕的文字,但檢索的方式卻極不相襯,只是在〔挑選文字〕,而不是在〔歸類文字〕,無法進行有效率的整合式學習。如果能使用適合的方法提升檢索效率,每次都能自動歸類〔結構相關〕的一系列單字,讓人可以輕鬆的去參照,日積月累,就能全面掌握文字的用法,還會越學越有興趣。
中文之所以檢索困難,主要原因就是古今字體的差距太大,許多文字已經演變出不同的形體,而缺少一種可以統合檢索的有效方法,因此人們都只能侷限於學習個別的字詞,見樹不見林,難以全面掌握文字的用法。但這在〔小篆〕的時代卻是很容易的事,因為秦代的小篆已經統一了多國的文字,每個字的偏旁都維持統一的形態,結構可以一目瞭然,整批式的檢索、學習都很容易,但由於〔隸變〕之後,很多偏旁都改變了形體,或減省了筆畫,導致辨識不易,於是出現了許多錯誤的解釋方式,世人皆以〔形似字體〕牽強附會,造成許多矛盾,無法貫通,直到東漢〔許慎〕創作了〔說文解字〕,才開啟了文字學的解析方式,為後世提供了一種有系統的研究及學習中文的方法。從此人們解釋文字才開始講求根據,〔說文解字〕在各種文字學的〔字書〕之中被廣泛的引用,兩千多年以來,人們從小習字多採用文字學的方法,只要瞭解了文字的結構內涵,就能舉一反三,貫通古今的文章。然而由於近代西風東漸,白話文興起,文字的學習也捨棄了傳統文字學的方法,而改用西方文字〔口語化〕的學習方式,但現代人不僅要學習口語的白話文,又要學習古典的文言文,並且還有〔簡繁體〕的各種差異,面對著數十萬的字詞,卻只能使用效率極低的檢索方式,所以現代人的學習過程相較於古代來說,確實是更為艱難了。
現代人雖然已經擁有了各種先進的數位化科技,但對於文字的學習卻反而退化到〔個別、零碎〕的口語化方式,其結果就是讓文字本身逐漸遺失〔組合、繁衍〕的性質,而像中文這種仍然保有高度〔模組化〕的文字,就應該充分利用數位化的檢索技術,整體的去學習文字,而不該只是零碎的查字,降低學習的效率。其實只要使用〔說文解字〕去解析中文的單字,就可發現每個單字的組成方式就像是詞彙一樣,也是同樣具有〔模組化〕的特性,除了少數幾百個獨體字之外,其他數以萬計的〔合體字〕都是由〔多重階層〕的單字所組合而成,並不像拼音文字的〔字首、字尾、字根〕大都只能對應到〔音節〕而無明顯的字義,理論上一定可以設計出比拼音文字更直觀、更嚴謹的〔關聯式〕檢索功能,只是由於技術的難度太高,坊間一直都沒有類似的作品問世。為了達成此理想,本字典採用〔說文解字〕的解析方式,重新去設計出一種〔複合式〕的字形結構,可以動態的查詢及顯示〔結構相關〕的單字,由於這樣擴大了文字理解的層面,所以更容易去聯想詞句的相關意義。而且檢索的方式相當便捷,若想要時常的複習,就會變得非常的容易。
一.〔偏旁樹〕
採用〔樹狀架構〕詳細解析單字的組成結構,同時列出〔小篆〕與〔楷書〕互相比對,還可打開每一層來觀察偏旁的位置及解析筆畫的變化,並且關連到〔詞彙列表〕,一個〔點選〕動作即可查看相關的解釋,省去繁瑣的查詢過程,提升學習的效率。
若對比西方文字的組字方式來看,拼音文字的〔字首、字尾、字根〕大部分都只是〔音節〕而非完整的單字,而中文則是一種〔以字組字〕的模組化文字,每個〔偏旁組件〕都是一個完整的單字,所以最適合使用多層的〔樹狀體〕來呈現其結構。
二.動態〔偏旁提示〕
根據指定的〔偏旁組合〕,在單字的〔字形〕中顯示高亮度的顏色,突顯出偏旁的位置。
由於中文是一種〔方塊〕文字,組成單字的每個〔偏旁〕並不像拼音文字的〔字母〕那樣直線排列、容易辨別,而是以〔多重階層〕的方式組合成一個方塊字,而且有些形體已經改變、或減省,導致不易辨識,但只需以高亮度的顏色標示出偏旁的位置,就能明確的呈現出原始的架構。
三.視覺化〔偏旁檢索〕
有別於市面上其他的字典採用固定式的〔部首表〕或口語式的〔注音、拼音〕去檢索單字,導致檢索的結果缺乏關聯性,而是採用〔文字學〕所定義的〔偏旁結構〕,動態的歸類單字,所以檢索的結果都具有明確嚴謹的關聯性。而且可以搜尋到單字的每個階層之中,再結合〔偏旁提示〕的功能,達到〔所見即所得〕的效果。
由於中西文字在組字原理上的不同,在經過了無數年代的〔語音演化〕之後,拼音文字的〔拼法〕會隨著口語而改變,並且大部分〔字首、字尾、字根〕都只是保留了音節,而不是完整的文字,而中文的〔口語〕雖然已經演化出不同的發音、方言,但〔文字〕本身獨立發展,並沒有隨著〔口語〕而改變,大部分的文字都保留了原始字形的完整結構。只要利用這種文字所保留的原始結構,就能從任何一個單字去搜尋出〔衍生意義〕的一系列單字。
四.快速〔詞彙檢索〕
可隨意輸入〔簡繁體、同義字〕,會自動找出正確的詞彙,只需輸入詞彙中的某幾個單字,其他不確定的部分就輸入問號(或空格)即可。會將查到的每條不同詞彙進行排序,依據輸入的〔已知字詞〕在詞彙中的位置作順序,並標示紅色,以提高肉眼查找的速度。
中文的特性就是每個單字都是固定大小的方塊,而且不會隨著使用詞句的不同而改變形態,不像〔拼音文字〕的長度不固定且多變化,所以中文單字在詞句中的位置就可以被精確的定位出來,而且排序之後還非常的整齊。利用這種〔方塊字〕的特性來設計〔詞彙檢索〕,就能讓使用者輕鬆快速的找到詞彙。
五.快速〔釋義翻查〕
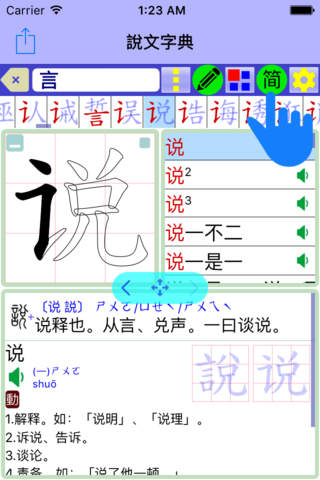
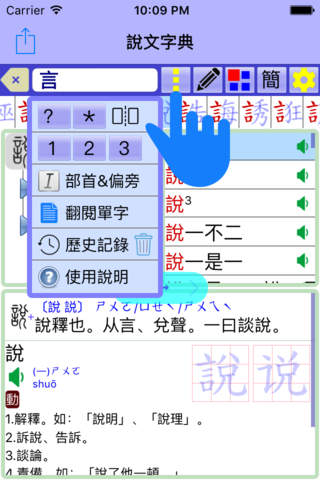
用〔單指〕點選〔釋義畫面〕中的字詞,即可查到解釋,並完整的紀錄查詢過程。可打開〔歷史紀錄〕點選過去的每一筆紀錄,可快速的恢復到每一個操作過的動作,包括〔偏旁樹、單字列表、詞彙列表〕皆可恢復到原來的狀態。這比書籤更好用,有助於重複的來回查看各種解釋。
六.完整〔收藏字詞〕
不僅是單純的收藏〔字詞〕本身的名稱,而是完整的收藏當前的查詢狀態,包括〔輸入內容、偏旁樹、單字列表、詞彙列表〕皆可完整的收藏起來,保存了所有的關聯性,隨時調用就能繼續當時的查詢步驟。
七.字體縮放自如
若有看不清楚的地方,就直接用〔兩指手勢〕隨時放大畫面。
八.詞彙發音
可輕鬆的聽取詞彙發音,不必花費眼力去看注音符號。
九.筆畫解析
在〔偏旁樹〕中對照〔小篆〕與〔楷書〕兩種字體,可清楚呈現文字的架構,此時點選〔楷書〕字體的偏旁,即可顯示出偏旁的〔筆順動畫〕,還可打開每一層來觀察每個偏旁的位置及筆畫的變化,也可將每個〔偏旁〕切換成〔單字〕來查看其獨立的筆順。
所謂的〔筆順標準〕一直都是人們的迷思,但事實上〔筆順〕並不能完全呈現在任何書寫完畢的文字之中,能夠呈現出來的只有文字的結構而已,因此世界上不論是何種語言,其文字本身的〔筆順〕並無一定的標準,最後書寫出來的字體是否〔正確、美觀〕才是重點。若對比西方文字來看,拼音文字是在寫出一個一個的〔字母〕,而中文是在寫出一個一個的〔偏旁〕,差別只在於拼音文字是單純的〔左右直線〕排列,而中文是複雜的〔多重階層〕排列,由於組合的方式更多,筆畫的交互關係就會更複雜,因此中文的〔筆順〕才會變成是一個議題。然而一般〔專家、學者〕在提出筆順原則時,都只是以整個〔單字〕為對象去強調〔下筆距離、書寫順暢〕等規則,而不是以結構中的〔偏旁〕為對象去解析筆順的問題,但既然〔筆順〕的問題是由於〔多重階層〕的排列方式所產生,所以〔筆順〕就應該跟結構中的每個偏旁有關。若對照〔小篆〕的字體去觀察就會更加清楚,因為〔小篆〕還未經過〔隸變〕的簡省過程,最能呈現出文字的整體結構,只有先掌握了文字的結構,筆順的問題才能迎刃而解,而不該捨本逐末,去盲目遵從任何一種〔筆順標準〕,這樣寫出來的字體才會正確、美觀。
十.筆畫練習
提供符合〔偏旁架構〕的筆畫練習,可在畫面上直接臨摹。可搭配〔筆畫解析〕,打開〔偏旁樹〕的每一層去觀察筆順,可看出每個字的整體筆順都跟〔偏旁架構〕有關。若想寫出一手好字,必須先寫對了偏旁,然後才能去發揮個人的創意。
十一.簡繁通查
可同時輸入〔簡繁〕字詞,〔偏旁檢索、詞彙檢索〕皆適用。也可隨時按下〔簡〕的按鈕,每個窗口都會切換字體,不會中斷任何操作狀態。